There’s evaluation theory, and then there’s evaluation in practice. When we’re evaluating international development or cooperation projects, it tends to be unpredictable. Evaluators have to think on our feet. We all have stories of when things did not go to plan.
Commissioners of evaluations ask us to be ever more rigorous and robust, while the subjects of our evaluations – the projects and programs – become more complex. I’m starting this new blog today to discuss international development evaluation in this context.
While I have a lot to say about evaluation, there’s also still so much I don’t know. This blog is a place for me to try out my ideas and to ask for those of others.
I’ve been blogging on a personal level for more than a dozen years, and now I’d like to turn some effort to Eval Thoughts: a place I can share insights from my work with clients and in the field, spark dialogue with my independent evaluator peers, and maybe shake things up a bit.
So, Welcome! I hope you’ll feel at home here: your blog source for unexpected evaluation topics, random sociology, notes from the field, critiques of accepted wisdom, and semi-unscripted rants about concrete problems we could change but never do. This is not the blog for templates and six-step methods. This is the blog for kvetching about how human endeavors don’t fit neatly into templates. It’s the blog for what we can do when the evaluation we’re doing becomes…
Messy, messy, messy
Does anyone else remember this guy from the Frosty the Snowman cartoon? (Caution: saying yes will mark you indelibly as Gen X.) The “worst magician in the world,” Dr. Hinkle, tries to pull some chickens out of a hat and ends up with eggs all over the floor: “Messy, messy, messy!” (The whole thing is here.)
Evaluation in international development spaces has gotten messier and messier, in part because the types of projects we’re evaluating are complicated, or even complex. Development partners (also called donors) are working more and more in institutional and policy space, encouraging reforms in places that may not have lots of incentives to change, and directing considerable attention to improving economic opportunities. Most of the ways development projects do this are not simple or straightforward.
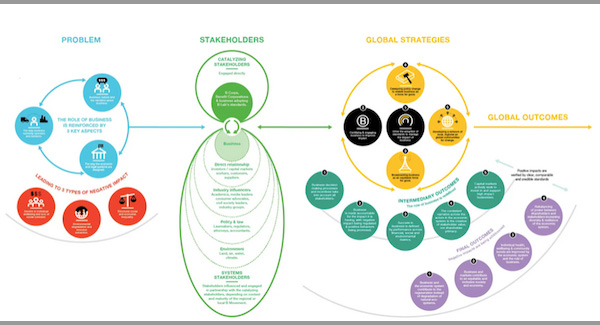
What does “not simple or straightforward” look like? It’s generally a long logic chain, or theory of change, like this one I found online:
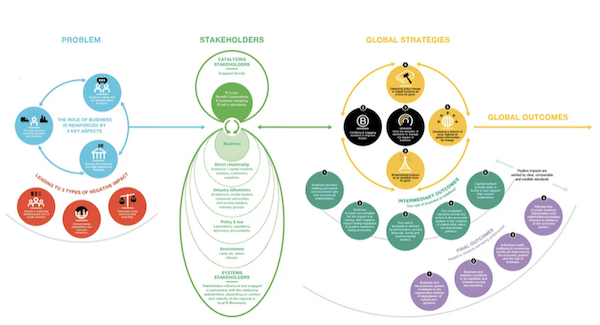
Graphics like this boil down where the problems come from, and put forth the hypothesis that:
IF we do this, this and this, and
IF our partners (government, private sector, whoever) do that, that, and the other
THEN then we’ll get to our intermediate results,
WHICH in turn will spur X, Y and Z,
IF the environmental conditions remain ripe…
THEN eventually (and not a little magically) the change we are seeking will emerge.
Talk about magic chickens. How on earth do funders think these complex, highly conditional plans will work? How do they expect us to evaluate them when they don’t?
[Side note: this graphic is gorgeous. I don’t know who the organization has doing their visualizations, but that person deserves a raise and, probably, a gallery show.]
Simple evaluative answers aren’t always forthcoming
When we evaluate something like this, it’s hard to know where to look: which level is key? Which link has broken down? Who are the spoilers and how do we get them on board? Will the elections (or the weather, or the debt repayment schedule, or other external variables) throw everything into chaos? Can we count on good economic conditions?
This is quite different from sending a shipment of seeds or vaccines to a country that needs them. Projects like that had their own challenges, but the logic behind them was linear – add (A) inputs to (B) context under (C) conditions, to get to (X) results.
By contrast, working on institutional and policy reform is multifaceted and subject to unwritten assumptions and unintended consequences. There are more places and more ways for them to go wrong – despite big budgets, top-notch and deeply committed implementing teams, and years of work.
Our evaluation role is mixed up in these challenges. I want to talk about what rigor looks like in environments like this, and about multiple causation, and measurement uncertainty. We need to talk about what commissioners of evaluation want, and what they can realistically have. There’s also a lot more room for local evaluation capacity that needs addressing.
This blog will ask questions like:
- Do MEL platforms and evaluation IDIQs produce better MEL services or are they just more convenient for donors’ procurement processes?
- Why are we still not taking the results back to program participants systematically?
- What makes people seem to “fall into” evaluation, rather than choosing it proactively? Does it matter?
- Why is evaluation of institutions still so fraught? Should international evaluators improve their methods somehow or would local evaluators be a stronger choice?
- What’s the value of creativity and operational independence in an evaluation? Why should funders celebrate it instead of ring-fencing it?
- What does it mean to decolonize methods in evaluation, and to work genuinely adaptively, and how can evaluators promote these in old-school client environments?
- How can we work better with local researchers, build genuine mutual capacity, and help them win work that normally goes to government contracting’s Usual Suspects?
If we can work together to minimize some of evaluation’s big mistakes, maybe we will get to try making some new, more interesting mistakes. I don’t think it’s wrong to court a little controversy about evaluation, so we don’t mistake the current situation for “state-of-the-art.” The ideal – for me! – would be discussions that make me dislodge and retool my own long-held beliefs, and make us all reflect on who evaluation is for.
Dear evaluators out there: Please come along on these discussions and be agentes provocateuses with me. Challenge me and challenge our industry. I’m not afraid to disagree. After all, I’m an evaluator: I’m used to eating lunch alone. I promise to be respectful (and will insist on the same from any commenters) while we look for new ground to sow together.